7.2 Bottom Up Parsing and Recognition
The basic idea of bottom up parsing and recognition is to begin with the concrete data provided by the input string --- that is, the words we have to parse/recognize --- and try to build bigger and bigger pieces of structure using this information. Eventually we hope to put all these pieces of structure together in a way that shows that we have found a sentence.
Putting it another way, bottom up parsing is about moving from concrete low-level information, to more abstract high-level information. And this is reflected in a very obvious point about any bottom up algorithm: In bottom up parsing, we use our CFG rules right to left.
What does this mean? Consider the CFG rule 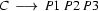 . Working bottom up means that we will try to find a P1, a P2, and a P3 in the input that are right next to each other. If we find them, we will use this information to conclude that we have found a C. That is, in bottom up parsing, the flow of information is from the right hand side of the rules to the left hand side of the rules.
. Working bottom up means that we will try to find a P1, a P2, and a P3 in the input that are right next to each other. If we find them, we will use this information to conclude that we have found a C. That is, in bottom up parsing, the flow of information is from the right hand side of the rules to the left hand side of the rules.
Let's look at an example of bottom up parsing/recognition. Suppose we're working with the grammar of English that was given earlier, and that we want to see whether the following string of symbols is a sentence:
vincent shot marsellus. Working bottom up, we might do the following. First we go through the string, systematically looking for strings of length 1 that we can rewrite by using our CFG rules in a right to left direction. Now, we have the rule 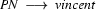 , so using this in a right to left direction gives us:
, so using this in a right to left direction gives us:
pn shot marsellus. But wait: we also have the rule 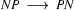 , so using this right to left we build:
, so using this right to left we build:
np shot marsellus It's time to move on. We're still looking for strings of length 1 that we can rewrite using our CFG rules right to left --- but we can't do anything with np. But we can do something with the second symbol, shot. We have the rule 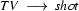 , and using this right to left yields:
, and using this right to left yields:
np tv marsellus Can we rewrite tv using a CFG rule right to left? No --- so it's time to move on and see what we can do with the last symbol, marsellus. We have the rule 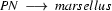 , and this lets us build:
, and this lets us build:
np tv pn But wait: we also have the rule so using this right to left we build:
np tv np Are there any more strings of length 1 we can rewrite using our context free rules right to left? No --- we've done them all. So now we start again at the beginning looking for strings of length 2 that we can rewrite using our CFG rules right to left. And there is one: we have the rule 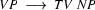 , and this lets us build:
, and this lets us build:
np vp Are there any other strings of length 2 we can rewrite using our CFG rules right to left? Yes --- we can now use 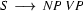 :
:
s And this means we are finished. Working bottom up we have succeeded in rewriting our original string of symbols into the symbol s --- so we have successfully recognized ``Vincent shot marsellus'' as a sentence.
Well, that was an example. A couple of points are worth emphasizing. This is just one of many possible ways of performing a bottom up analysis. All bottom up algorithms use CFG rules right to left --- but there many different ways this can be done. To give a rather pointless example: we could have designed our algorithm so that it started reading the input in the middle of the string, and then zig-zagged its way to the front and back. And there are many much more serious variations --- such as the choice between depth first and breadth first search --- which we shall discuss next week.
In fact, the algorithm that we used above is crude and inefficient. But it does have one advantage --- it is easy to understand, and as we shall soon see, easy to put into Prolog.