15.2 A Top-down Generator
A natural language generator is a program which, given a semantic representation and a grammar, produces a sentence which, according to the grammar, is grammatical and corresponds to the semantic representation. In this section, we will see a generator that works in a top-down fashion, i.e., it will build a syntactic structure starting at the top and working its way down to the words. Just the way top-down parsers worked. Accordingly, the generator will read grammar rules from left to right and will try to split up the semantic input into semantic representations that correspond to smaller and smaller constituents.
Here is the general idea of how the top-down generator works. Let's say that we want to generate a sentence corresponding to the semantic representation 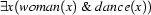 . Our grammar tells us that to build a sentence, we have to build a noun phrase and a verb phrase (
. Our grammar tells us that to build a sentence, we have to build a noun phrase and a verb phrase (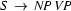 ). The part of our input that corresponds to the noun phrase is
). The part of our input that corresponds to the noun phrase is 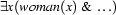 and the part that corresponds to the verb phrase is
and the part that corresponds to the verb phrase is 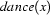 . So, we now have to build a noun phrase corresponding to the semantics . Let's say we have the grammar rule
. So, we now have to build a noun phrase corresponding to the semantics . Let's say we have the grammar rule 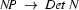 . That means we have to split the semantic representation in the part correspondig to the determiner (
. That means we have to split the semantic representation in the part correspondig to the determiner (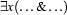 ) and the part corresponding to the noun (
) and the part corresponding to the noun (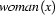 ), and then generate an appropriate determiner (such as a) and an appropriate noun (such as woman). Then we proceed similarly for the verb phrase. In the end, we will have built a syntactic structure (
), and then generate an appropriate determiner (such as a) and an appropriate noun (such as woman). Then we proceed similarly for the verb phrase. In the end, we will have built a syntactic structure (s(np(det(a), n(woman)), vp(iv(dances))) for example) that corresponds exactly to our input semantics.
But how do we know how to split up the semantic representation? How did we, e.g., know that corresponded to the noun phrase and that corresponded to the verb phrase? Well, this has to be encoded in the part of our grammar that takes care of semantic construction. The grammar that we are going to use in this section is a feature-based grammar which does semantic construction (in the feature semF) and furthermore uses the feature syn to store the syntactic structure of constituents in the categories. Here it is:
%%% phrase structure rules
S ---> [NP,VP] :-
S = [cat:s,
semF:[sem:NPSem|_],
syn:s(NPSyn,VPSyn)|_],
NP = [cat:np,
semF:[sem:NPSem, var:X, scope:VPSem|_],
syn:NPSyn|_],
VP = [cat:vp,
semF:[sem:VPSem, arg1:X|_],
syn:VPSyn|_].
NP ---> [Det, N] :-
NP = [cat:np,
semF:[sem:DetSem, var:X, scope:R|_],
syn:np(DetSyn,NSyn)|_],
N = [cat:n,
semF:[sem:NSem, arg:X|_],
syn:NSyn|_],
Det = [cat:det,
semF:[sem:DetSem, var:X, restr:NSem, scope:R|_],
syn:DetSyn|_].
VP ---> [IV] :-
VP = [cat:vp,
semF:IVSemF,
syn:vp(IVSyn)|_],
IV = [cat:iv,
semF:IVSemF,
syn:IVSyn|_].
VP ---> [TV, NP] :-
VP = [cat:vp,
semF:[sem:NPSem, arg1:X|_],
syn:vp(TVSyn,NPSyn)|_],
TV = [cat:tv,
semF:[sem:TVSem, arg1:X, arg2:Y|_],
syn:TVSyn|_],
NP = [cat:np,
semF:[sem:NPSem, var:Y, scope:TVSem|_],
syn:NPSyn|_].
%%% lexical rules
%%% determiner
lex(a,Det) :-
Det = [cat:det,
semF:[sem:exists(X,R,S), var:X, restr:R, scope:S|_],
syn:det(a)|_].
lex(every,Det) :-
Det = [cat:det,
semF:[sem:forall(X,R,S), var:X, restr:R, scope:S|_],
syn:det(every)|_].
%%% common nouns
lex(gun,N) :-
N = [cat:n, semF:[sem:gun(X), arg:X|_], syn:n(gun)|_].
lex(robber,N) :-
N = [cat:n, semF:[sem:robber(X), arg:X|_], syn:n(robber)|_].
lex(man,N) :-
N = [cat:n, semF:[sem:man(X), arg:X|_], syn:n(man)|_].
lex(woman,N) :-
N = [cat:n, semF:[sem:woman(X), arg:X|_], syn:n(woman)|_].
%%% verbs
lex(dies,IV) :-
IV = [cat:iv, semF:[sem:die(X), arg1:X|_], syn:iv(dies)|_].
lex(loves,TV) :-
TV = [cat:tv, semF:[sem:love(X,Y), arg1:X, arg2:Y|_], syn:tv(loves)|_].
lex(shoots,TV) :-
TV = [cat:tv, semF:[sem:shoot(X,Y), arg1:X, arg2:Y|_], syn:tv(shoots)|_].15.2.1 First Try
Consider the following algorithm for top-down generation:
Your input is a feature structure which has
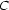 as the value of its feature
as the value of its feature 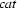 and
and 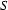 as the value of
as the value of 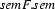 . Your current goal therefore is to generate a constituent of category corresponding to the semantics .
. Your current goal therefore is to generate a constituent of category corresponding to the semantics .Select a grammar rule
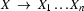 , such that
, such that 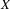 contains the feature-value pair
contains the feature-value pair 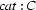 and unifies with the value of the feature in .
and unifies with the value of the feature in .Do steps 1 to 3 for all
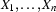 .
.
To understand how it works let's see what happens when we call it with the input
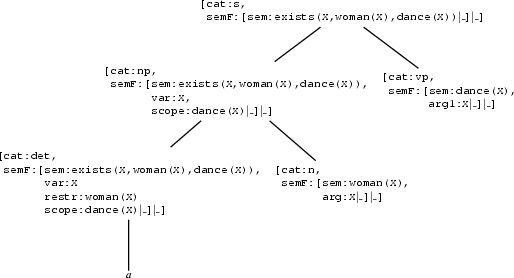
[cat:s, semF:[sem:exists(X,woman(X),dance(X))|_]|_]The algorithm will use the s-rule of our grammar (reading it left to right) to expand the syntactic structure we are building in a top-down fashion. The rule also tells us that the semantic representation associated with the np is the same as the semantic representation associated with the s node. Note, however, that the semantics of the vp node is not yet instantiated, because we haven't found out yet what the inner structure of the np is. Once we know what is the scope of the np, we will also know what's the semantics of the vp.

Next, we will expand the np node. This gives us the followig state. Again, the semantics of the np is passed in to the determiner, while the semantics of the noun cannot be determined yet. But we do know that it is identical to the restriction of the determiner.
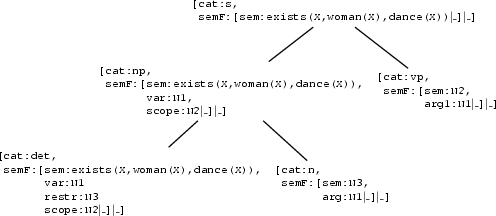
In the next step, we will match the determiner against the lexicon. The only lexical entry that unifies is the one for a. This unification will also lead to the following instantiations.
N1 = X
N2 = dance(X)
N3 = woman(X)So, we know now what is the semantics corresponding to the noun and the verb phrase respectively.
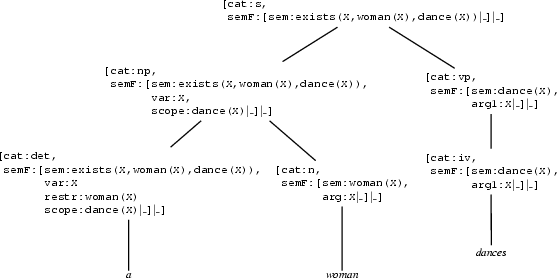
In the next step, the n node will be matched against the lexicon, giving us the word woman and then we will generate the verb dances by first expanding the vp node to an iv node and then matching against the lexicon. The result is:
Now, let's see what happens if we start from the semantic representation
forall(Y,man(Y),exists(X,woman(X),love(Y,X))). The beginning is very much like in the previous example. After we have successfully generated the noun phrase every man, we are in the following situation:
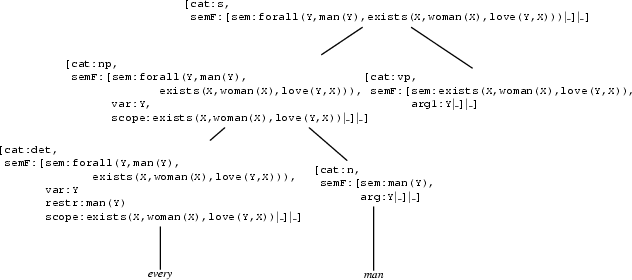
Now, we will have to generate a verb phrase. We will notice that the rule expanding the vp node to an iv doesn't help, because there is no intransitive verb with a matching semantics. So, we use the other vp rule. That gives us:

The next thing the algorithm will try to do is to generate a transitive verb. However, the semantics of this transitive verb is not yet specified at all. Which means that it will blindly produce transitive verbs hoping that they might fit with what's needed. This is of course not desirable. It would be much better if we would first generate the np with the semantics exists(X,woman(X),love(Y,X)). While doing so, we would find out that the semantics of the tv should be love(Y,X). So, the problem seems to be that it is not always correct to generate all constituents required by a rule on its right hand side simply from left to right. We should treat those of which we already know the semantics first. Let's see whether we can fix that.
15.2.2 Second Try
Here is an improved top-down generation algorithm, that generates constituents only once it know what their semantic content is.
Your input is a feature structure which has
as the value of its feature and as the value of . Your current goal therefore is to generate a constituent of category corresponding to the semantics .Select a grammar rule
, such that contains the feature-value pair and unifies with the value of the feature in .Do steps 1 to 3 for an
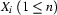 , such that the value of in
, such that the value of in 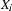 is instantiated. Then do the same for the remaining .
is instantiated. Then do the same for the remaining .
Here is what will happen in the problematic example. Up to the point where we have

everything is the same as above. But then we will postpone expanding the tv node, because the semantics feature is not instantiated. The semantics feature of the np node is instantiated, so that we expand that node. Applying the np rule and looking up the determiner in the lexicon instantiates N4 with love(Y,X) and N5 with X. This gives us:
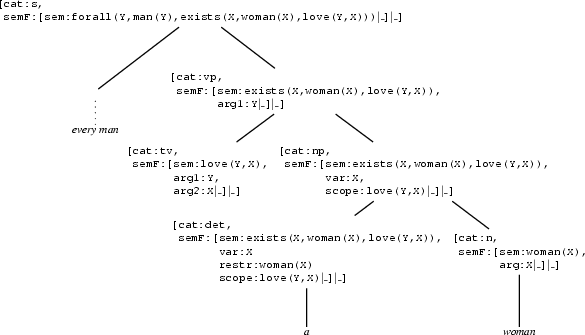
Note, how retrieving the determiner from the lexicon determined the value of its restriction and scope. Therefore we now know that the semantics of the noun should be woman(X) and the semantics of the verb should be love(Y,X).