6.2 DCGs for Long Distance Dependencies
Context free rules work locally. For example, the rule
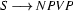
tells us how an S can be decomposed into two parts, and NP and a VP.
But certain aspects of natural language seem to work in a non-local, long-distance way. Indeed, for a long time it was thought that such phenomena meant that grammar-based analyses had to be replaced by very powerful new mechanisms (such as the transformations used in transformational grammar).
In fact, a surprising amount can be done by using grammars enriched in a fairly restricted way: namely, by the addition of features. Now, we've already discussed the use of features to deal with simple facts of case, but it turns out that features can do a lot more work for us. In particular, they do make it possible to give grammar-based analyses of many long distance phenomena.
We're now going to discuss a central long distance phenomenon (namely, English relative clauses) and show that DCGs enable us to give a rather neat feature-based analysis of such phenomena. The technique we are going to use is called threading. We will then use the same technique for an analysis of English wh-questions.
6.2.1 Relative Clauses
Consider these two English NPs. First, an NP with an object relative clause:
``The witch who Harry likes''. |
Next, an NP with a subject relative clause:
``Harry, who likes the witch.'' |
What is their syntax? That is, how do we build them? I'm going to start off by giving a fairly traditional explanation in terms of clauses are in terms of movement, gaps, extraction, and so on. As we'll soon see, it's pretty easy to think of these ideas in terms of features, and to implement them using DCGs.
The traditional explanation basically goes like this. We have the following sentence:
Harry likes the witchWe can think of the NP with the object relative clause as follows.
-----------------------
| |
the witch who Harry likes GAP(NP)That is, we can think of it as being formed from the original sentence by (1) extracting the NP ``the witch'' from its original position, thereby leaving behind an empty NP, or an NP-gap, and (2) moving it to the front, and (3) inserting relative pronoun ``who'' between it and the gap-containing sentence
What about the subject relative clause example? We can think of this as follows:
-----------
| |
Harry, who GAP(NP) likes the witchThat is, we have (1) extracted the NP ``Harry'' from the subject position, leaving behind an NP-gap, (2) moved it to the front, and (3) placed the relative pronoun ``who'' between it and the gap-containing sentence.
But why are relative clause constructions an example of unbounded dependencies? The word `dependency' indicates that the moved NP is linked, or depends on, its original position. The word `unbounded' is there because this ``extracting and moving'' operation can take place across arbitrary amounts of material. For example, from
A witch who Harry likes, likes a witch.we can form
------------------------------------------
| |
a witch, who a witch who Harry likes, likes GAP(NP)And we can iterate such constructions indefinitely --- albeit, producing some pretty hard to understand sentences. For example, from:
A witch who a witch who Harry likes, likes a witch.we can form
-----------------------------------------------------
| |
a witch who a witch who a witch who Harry likes, likes GAP(NP)In what follows we shall see that, by using features, we can give a nice declarative account of the basic facts of English relative clauses. Indeed, we won't even have to think in terms of movement. We'll just need to think about what information is missing from where, and how to keep track of it.
6.2.2 A First DCG
Let's now sit down and write a DCG for simple English relative clauses. In this DCG we will only deal with transitive verbs (verbs that take a single NP as argument --- or to use the proper linguistic terminology, verbs that subcategorize for a single NP). Further, to keep things simple, the only relative pronoun we shall deal with is ``who''.
Let's first look at the NP rules:
np(nogap) --> det, n.
np(nogap) --> det, n, rel.
np(nogap) --> pn.
np(nogap) --> pn, rel.
np(gap(np)) --> []. The first four rules are probably familiar. They say that an English NP can consist of a determiner and a noun (for example: ``a witch''), or a determiner and a noun followed by a relative clause (for example: ``a witch who likes Harry''), or a proper name (for example: ``Harry''), or a proper name followed by a relative clause (for example: ``Harry, who likes a house-elf''). All these NPs are `complete' or `ordinary' NPs. Nothing is missing from them. That is why the extra argument on NP contains the value nogap.
What about the fifth rule? This tells us that an NP can also be realized as an empty string --- that is, as nothing at all. Obviously this is a special rule: it's the one that lets us introduce gaps. It says: we are free to use `empty' NPs, but such NPs have to be marked by a feature which says that they are are special. Hence in this rule, the value of the extra argument is gap(np). This tells us that we are dealing with a special NP --- one in which the usual NP information is absent.
The use of features to keep track of whether or not information is missing, and if so, what kind of information is missing, is the crucial idea underlying grammar-based treatments of all sorts of long distance dependency phenomena, not just relative clauses. Usually such features keep track of a lot more information than our simple nogap versus gap(np) distinction --- but as we are only looking at very simple relative clauses, this is all we'll need for now.
Now for the S and VP rules.
s(Gap) --> np(nogap),vp(Gap).
vp(Gap) --> v(1), np(Gap). The first rule says that an S consists of an NP and a VP. Note that the NP must have the feature nogap. This simply records the fact that in English the NP in subject position cannot be realized by the empty string (in some languages, for example Italian, this is possible in some circumstances). Moreover, note that the value of the Gap variable carried by the VP (which will be either nogap or gap(np), depending on whether the VP contains empty NPs) is unified with the value of the Gap variable on the S. That is, we have here an example of feature passing: the record of the missing information in the verb phrase (if any) is passed up to the sentential level, so that we have a record of exactly which information is missing in the sentence.
The second rule says that a VP can consist of an ordinary transitive verb together with an NP. Note that instead of using the symbol tv for transitive verbs, we use the symbol v marked with an extra feature (the 1). (In the following section we shall introduce a second type of verb, which we will call v(2) verbs.) Also, note that this rule also performs feature passing: it passes the value of Gap variable up from the NP to the VP. So the VP will know whether the NP carries the value nogap or the value gap(np).
Now for the relativization rules:
rel --> prorel, s(gap(np)).
rel --> prorel, vp(nogap). The first rule deals with relativization in object position --- for example, the clause ``who Harry likes'' in ``The witch who Harry likes''. The clause ``who Harry likes'' is made up of the relative pronoun ``who'' (that is, a prorel) followed by ``Harry likes''. What is ``Harry likes''? It's a sentence that is missing its object NP --- that is, it is a s(gap(np)), which is precisely what the first relativization rule demands.
Incidentally --- historically, this sort of analysis, which is due to Gerald Gazdar, is extremely important. Note that the analysis we've just given doesn't talk about moving bits of sentences round. It just talks about missing information, and says which kind of information needs to be shared with the mother category. The link with the movement story should be clear: but the new information-based story is simpler, clearer and more precise.
The second rule deals with relativization in subject position --- for example, the clause ``who likes the witch'' in ``Harry, who likes the witch''. The clause ``who likes the witch'' is made up of the relative pronoun ``who'' (that is, a prorel) followed by ``likes the witch''. What is ``likes the witch''? Just an ordinary VP --- that is to say, a vp(nogap) just as the second relativization rule demands.
And that's basically it. We only have to add a few lexical rules and we're ready to go. Here's some lexicon:
n --> [house-elf].
n --> [witch].
pn --> [harry].
det -->[a].
det -->[the].
v(1) --> [likes].
v(1) --> [watches].
prorel --> [who].Let's look at some examples. First, let's check that this little DCG handles ordinary sentences:
s(_,[harry,likes,the,witch],[]).
yesLet's now check that we can build relative clauses. First, object position relativization:
np(_,[the,witch,who,harry,likes],[]).
yesNow subject position relativization:
np(_,[harry,who,likes,the,witch],[]).
yesAnd of course, there's no need to stop there --- we can happily embed such constructions. For example, combining the last two examples we get:
np(_,[the,witch,who,harry,who,likes,the,witch,likes],[]).
yesAnd indeed, we really are correctly handling an unbounded construction. For example, we can form:
np(_,[a,witch,who,a,witch,who,harry,likes,likes],[]).And we go on to add another level:
np(_,[a,witch,who,a,witch,who,a,witch,who,harry,likes,likes,likes],[]).But this is getting hard to understand --- so let's simply check that we can make sentences containing relative clauses and then move on:
s(_,[a,house-elf,likes,a,house-elf,who,a,witch,likes],[]).6.2.3 A Second DCG
Our first DCG works, but it only covers a tiny fragment of English. So let's try and improve it a bit.
Now, one obvious thing we could do is to add further relative pronouns, like ``that'' and ``which'', so that we could deal with such sentences as:
``The broomstick which was in Harry's room flew down to the lake''. |
and
``The castle that the four wizards built is called Hogwarts'', |
and
``The house-elf that was in the kitchen cried''. |
But making this extension is not particularly difficult. The basic point is that ``who'' can only be be used with conscious entities (such as wizards, witches, and house-elves), while ``which'' has to be used with entities that lack consciousness (such as broomsticks), while ``that'' can be used with both. So all we'd need to do is introduce a feature which could take the values consc and unconsc, mark the nouns in the lexicon appropriately, and then extend the DCG so that this information was taken into account when forming relative clauses. It's a good exercise, but I won't discuss it further.
A far more interesting extension is to add new kinds of verbs --- that is, verbs with different subcategorization patterns. In what follows we'll discuss verbs such as ``give'' which subcategorize for an NP followed by a PP.
Consider the following sentence:
``The witch gave the house-elf to Harry''. |
We can relativize the NP argument of ``give'' (that is, the NP ``the house-elf'') to form:
``the house-elf who the witch gave to Harry''. |
Moreover, we can also relativize the NP that occurs in the PP ``to Harry''. That is, we can take ``Harry'' out of this position, leaving the ``to'', behind to form:
``Harry, who the witch gave the house-elf to''. |
We would like our DCG to handle such examples.
But note --- there are also some things that the DCG should not do, namely perform multiple extraction. There are now two possible NPs that can be moved: the first argument NP, and the NP in the PP. Can both be moved at once? In some languages, yes. In English, no. That is, in English
|
 ``The house-elf who the wizard gave'',
``The house-elf who the wizard gave'',is not an NP. So when we write our DCG, not only do we have to make sure we generate the NPs we want, we also have to make sure that we don't build NPs using multiple extraction.
Now, we can develop our previous DCG to do this --- but the result is not something a linguist (or indeed, a computational linguist) should be proud of. Let's take a closer look.
As we are going to need to build prepositional phrases, we need a rule to build them:
pp(Gap) --> p,np(Gap).This says: a prepositional phrase can be built out of a preposition followed by an NP. We have used the extra argument to pass up the value of the Gap feature from the NP to the PP. So the PP will knows whether the NP is ordinary one, or a gap.
We'll also need a bit more lexicon: we'll add the verb ``gave'' and the preposition ``to'':
v(2) --> [gave].
p --> [to].Now comes the crucial part: the new VP rules. We need to allow single extractions, and to rule out double extractions. Here's how this can be done --- and this is the part linguists won't like:
vp(Gap) --> v(2), np(nogap),pp(Gap).
vp(Gap) --> v(2), np(Gap),pp(nogap).We have added two VP rules. The first rule insists that the NP argument be gap-free, but allows the possibility of a gap in the PP. The second rule does the reverse: the NP may contain a gap, but the PP may not. Either way, at least one of the VPs two arguments must be gap-free, so multiple extractions are ruled out.
Now, this does work. For example it generates such sentences as:
s(_,[the,witch,gave,the,house-elf,to,harry],[]).
yesAnd we can relativize in the NP argument:
np(_,[the,house-elf,who,the,witch,gave,to,harry],[]).
yesAnd in the PP argument:
np(_,[harry,who,the,witch,gave,the,house-elf,to],[]).
yesMoreover, the DCG refuses to accept multiple extractions, just as we wanted:
np(_,[the,house-elf,who,the,wizard,gave],[]).
noSo why would a linguist not approve of this DCG?
Because we are handling one construction --- the formation of VPs using V(2) verbs --- with two rules. |
The role of syntactical rules is to make a structural claim about the combination possibilities in our language. Thus there should be one rule for building VPs out of V(2) verbs, for there is only one structural possibility: V(2) verbs take an NP and a PP argument, in that order. We used two rules not because there were two possibilities, but simply to do a bit of `feature hacking': by writing two rules, we found a cheap way to rule out multiple extractions. But this is a silly way to write a grammar. As we saw when we discussed the case example, one of the roles of features is precisely to help us minimize the number of rules we need --- so to add add extra rules to control the features is sheer craziness!
There are also practical disadvantages to the use of two roles. For a start, many unambiguous sentences now receive two analyses. For example,
``The witch gave the house-elf to Harry'' |
is analyzed two distinct ways. Such spurious analyses are a real nuisance --- natural language is ambiguous enough anyway. We certainly don't need to add to our troubles by writing DCGs in a way that guarantees that we generate too many analyses!
Furthermore, adding extra rules is just not going to work in the long run. As we add more verb types, we are going to need more and more duplicated rules. The result will be a mess, and the grammar will be ugly and hard to maintain. We need a better solution --- and there is one.
6.2.4 Gap Threading
The basic idea underlying gap threading is that instead of using simple feature values such as nogap and gap(np) we are going to work with more structure. In particular, the value of the Gap feature is going to be a difference list. Think of the first list as ``what we have before we find analyze this category'' and the second item as ``what we afterwards''. Or more simply: think of the first list as the ``in'' value, and the second item as the ``out'' value.
Here are the new NP rules:
np(F-F) --> pn.
np(F-F) --> pn,rel.
np(F-F) --> det,n.
np(F-F) --> det,n,rel.
np([gap(np)|F]-F) --> []. Note that in the first four rules, the difference list F-F is doing the work that nogap used to do. And this is the way it should be. After all, F-F is a difference list representation of the empty list. So, for example, the first rule says that an NP can consist of a proper name, and when an NP is built that way, no material has been removed. (That is: the in value is the same as the out value.)
What about the last rule? This says that we can build empty NPs, but that when we do so, we have to add gap(np) to the first list. That is, in this case there is a difference between the in values and the out values: the difference is precisely the gap(np) value.
The S rule is analogous to our old one:
s(F-G) --> np(F-F),vp(F-G). This says that the subject NP must be an ordinary NP (recall: F-F is essentially the same as nogap and that the difference list associated with the VP is passed up to the S. That is, just as before we are performing feature passing, except that now the Gap feature is a difference list.
Thus the rules for PPs and relativization should not be puzzling:
pp(F-G) --> p,np(F-G).
rel --> prorel,s([gap(np)|F] - F).
rel --> prorel,vp(F-F).Once again, these are exact analogs of our earlier rules --- except that we are using complex features.
So we come at last to the critical part: how do we handle VPs? As follows:
vp(F-G) --> v(1),np(F-G).
vp(F-G) --> v(2),np(F-H),pp(H-G). This looks nice: we have one rule for each of the verb types. The first rule is is analogous to our earlier V(1) rule. But what about the second rule? Why do we only need one for V(2) verbs?
Think about it. The most complicated feature we have is
[gap(np)|F]-F] and this indicates that precisely one element is missing. So when we enter the second VP rule, there is only one missing item and two arguments. It may end up in the first position, or the second, but (as there is only one) it cannot end up in both.
This DCG is well worth studying. For a start, you should carefully compare it with our previous DCG. Note the systematic link between the two. Second, you really should play with lots of traces so you can see how the gap is threaded in and out of the various categories.
This threading technique can be used to thread other things besides gaps. For example, it can be used in computational semantics. There is a simple way of implementing Discourse Representation Theory (DRT): one threads the semantic representations (the DRSs) through the parse tree. In this way, each part of the sentence gets to make its own semantic contribution. You can find a discussion of this in Volume 2 of the textbook on semantics by Blackburn and Bos, which is available at www.comsem.org.
6.2.5 Questions
As we have promised above, we now apply the technique of gap threading to another phenomenon: wh-questions. Let us look at an example:
Harry likes the witch
--Who likes the witch?So we can think of this we-question as a sentence with a gap:
----
| |
Who GAP(NP) likes the witch?If we want to ask about the witch, not about Harry, we form the following question:
-------------------
| |
Who does Harry like GAP(NP)?So this looks very much like the analysis of relative clauses that we had in the previous paragraph, except for one small complication: When we ask about the object, we have to use an auxiliary and the infinite form of the verb ("does...like").
We have said that relative constructions are a case of unbounded dependencies: an arbitrary amount of material may stand between the gap and the extracted and moved noun phrase. The same holds for wh-questions: From a sentence like
Harry said that a witch likes Ron.we can get to the question
-------------------------------
| |
Who did Harry say that a witch likes GAP(NP)?And of course we can make the question even longer, for example like this:
-------------------------------------------------------
| |
Who did Hermione say that Harry said that a witch likes GAP(NP)?
%subject interrogative
s(F-F) --> wh, vp(F-F,fin).
% object interrogative
s(F-F) --> wh, aux, np(F-F), vp([gap(np)|F]-F, infin).
vp(F-G, FIN) --> v(1, FIN),np(F-G).
vp(F-G) --> v(2, FIN),np(F-H),pp(H-G).