2.3 Morphological Analysis with Finite State Transducers
Morphology is about the internal structure of words. It asks: What are the building blocks - the morphemes - that a word is constructed from and what is the meaning of these blocks? And what are the rules by which these building blocks can be combined to form words? ``wizard'', for instance, consists of only one morpheme, namely wizard, while ``wizards'' consists of two morphemes, namely wizard and s where s contributes the plural. ``kissed'' also consists of two morphemes, namely kiss and the past tense ed.
Morphology is an area of computational linguistics where finite state technology has been found to be particularly useful, because for many languages the rules after which morphemes can be combined to build words can be caputered by finite state automata. So, it is possible to write finite state transducers that map the surface form of a word to a description of the morphemes that constitute that word or vice versa. They map, for instance, wizard+s to wizard+PL or kiss+ed to kiss+PAST.
As a simple example, we will now look at plural nouns in English. The default rule is of course to just add an s as in wizard+s. Then there are some stems which take es to form the plural, like witch e.g. This can be explained by morpho-phonological rules that insert an e whenever the morpheme preceding the s ends in s, x, ch or another fricative. For simplicity, we will assume here that there are two types of regular stems: those that take an s to form the plural and those that take an es. Finally there are clearly irregular forms like mouse and mice or automaton and automata.
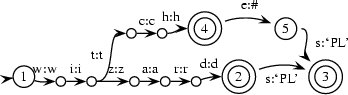
So, we want a transducer that translates wizard+s into wizard+PL, witch+es into witch+PL, mice, into mouse+PL and automata into automaton+PL. Here is one that uses categories:
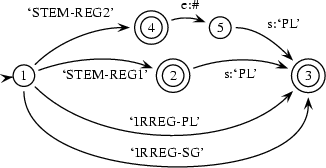
lex(wizard:wizard,`STEM-REG1').
lex(witch:witch,`STEM-REG2').
lex(automaton:automaton,`IRREG-SG').
lex(automata:`automaton-PL',`IRREG-PL').
lex(mouse:mouse,`IRREG-SG').
lex(mice:`mouse-PL',`IRREG-PL').
...
Now, this transducer assumes that the words come already split up at their morpheme boundaries; if it was Prolog it would assume input of the form [wizard,s] or [witch,es] on the first tape. This is no probleme however, because we can use another transducer to do this. Then we can use these two transducers in a cascade, i.e. we let the morphological transducer above run on the output of the splitting transducer. But this means that we can also compose them into a single transducer that does both jobs. This transducer would look something like this: