CSc 538
DSM research highlights: a blog
What follows are highlights of some of the mental processes I worked
through
during Phase 1 of the project. The purpose of this log is not to show
you
exactly what you should have noticed in your research, but to give a
concrete
example of how the process works. It will help to have the DSM paper
handy
as you read through this.
I found the original 1985 paper by Copeland and Khoshafian, which I will
hereafter
refer to as CK85, in the ACM digital library.

CK85: page 1, 1st column
The second paragraph in the paper sets the tone. This will be a direct
comparison with
the N-ary storage model. The authors say they're not taking a "we are
always
better" tone, so I should be able to find both advantages and
disadvantages
straight away.
This example explains the entire concept. Each attribute is its own
table.
Based on the context, the authors seem to be using the word "surrogate"
for "key". Ok.

CK85: page 1, 2nd column
The two copies, both using cluster indexing, are important. There will
be
a space issue with this model.
Section 2 appears to be listing all the advantages. Some may not be
worth
mentioning due to their limited applicability, like the multivalued
attribute support
in 2.1 (that means it's not even in 1NF!) and the directed graphs of
2.5. Some would
make good examples though, like the heterogeneous records of 2.4, which
eliminates nulls.

CK85: page 3, 1st column
This is now the second time something called an "inverted file" has been
mentioned. Nothing in our class slides about it. Our textbook has
a passage about "fully inverted files" on p. 486, which is a file that
has a
secondary index on every attribute. On a whim, I type "inverted file"
into
Google to see what I get. It leads to me to pages on document searching
and information retrieval. This is probably related, but it's a dead
end as
far as finding a straightforward definition. I may have to look this up
elsewhere
if CK85 uses this term more.
Section 2.6 of CK85 lists differential file support as an advantage. I
check
out the Severance and Lohman reference, SL76, to make sure I know what
they mean.

Severance and Lohman: page 2
SL76 gives a good analogy to an errata list that I can use (and cite, of
course).
Now that the definition of a differential file is confirmed, the way the
DSM
allows the "errata list" to contain just the changed attribute
instead of
the entire record makes sense as an advantage for the DSM.

CK85: page 4, 1st column
Inverted files again. I better figure this out before going on.
Luckily, there's
a reference this time. After reading the first two pages of the
Cardenas
reference on inverted files, it seems definitely to be an index:
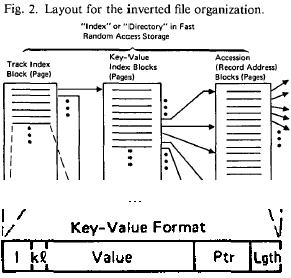
Cardenas: page 2
Oh goody, a picture. The format of the entries appears to be a value
for the entry,
a pointer to the record, and then some length entry telling you how many
pointers
you've got. (And so there may be more than one pointer.) Using this I
should be
able to come up with a small example of my own:
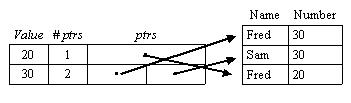
Inverted file example
So this would be the inverted file index on the "Number" attribute of my
sample
table. Look familiar? It's slide 59 from the notes! It's one of the
implementation
options for a secondary index. This is confirmed by the textbook's
definition
of a fully inverted file, which has a lot of such indexes. Ok, so an
inverted file
is just a secondary index.
Section 3.1 lists the N-ary model as having up to a 4-to-1 advantage in
space
over DSM. Definitely a shortcoming to acknowledge. The rest of section
3 appears
to show why the authors believe this isn't so much a concern.
The graphs in Section 5 can be pretty daunting, but decipherable after
all the
acronyms like "nca" and "njr" are defined. I can use a couple of the
graphs
as examples.
Conclusions
My own research into DSM eventually led me to consult three other papers
about related subjects besides the original, as well as the textbook and
other notes.
Your mileage may vary. Remember, the point of this was to show you the
process
in action and to give you something with which to compare your own work.
Here are the slides that I created as a result of
my own
research. Compare them to yours so you can see the level of detail I'm
looking
for. (I recommend downloading them instead of looking at them via the
web since I left notes on many slides that will be helpful to you in
understanding what I would be talking about with each slide.)
Back to Project page