9.3 Using Left-corner Tables
This left-corner recognizer handles the example that was problematic for the pure top down approach much more efficiently. It finds out what is the category of vincent and then doesn't even try to use the rule 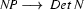 to analyze this part of the input. Remember that the top-down recognizer did exactly that.
to analyze this part of the input. Remember that the top-down recognizer did exactly that.
But how about the example that was problematic for the bottom-up approach? Here, we don't see any improvement, yet. Just like the bottom up recognizer, the left-corner recognizer will first try to analyze plant as a transitive verb. Let's see step by step what the left-corner recognizer defined above does to process the plant died given the grammar
|
|
|
|
|
|
|
|
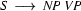
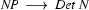
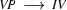
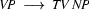
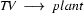
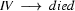
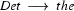
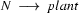
We will only show how the parse tree developes.
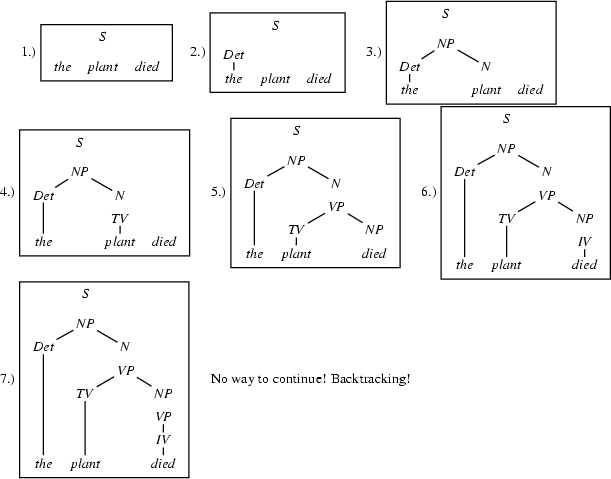
So, just like the bottom-up recognizer, the left-corner recognizer chooses the wrong category for plant and needs a long time to realize its mistake. However, the left-corner recognizer provides the information that the constituent we are trying to build at that point is a noun. And nouns can never start with a transitive verb according to the grammar we were using. If the recognizer would use this information, it would notice immediately that the lexical rule relating plant to the category transitive verb cannot lead to a parse. The solution is to record this information in a table. This left-corner table stores which constituents can be at the left-corner of which other constituents. For the little grammar of the problematic example the left-corner table would look as follows:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
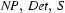
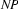
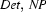
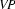
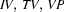
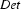
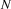
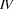
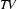
Note, how every category can be at the left corner of itself. In Prolog, we will simply store this table as facts in the knowledge base:
lc(np,s).
lc(det,np).
lc(det,s).
lc(iv,vp).
lc(tv,vp).
lc(X,X).Now, we can check every time that we choose a rule whether it makes sense to use this rule given the top-down information about the category that we are trying to recognize.
So, every time we decided on a category for a word, we first look into the left-corner table to check whether the category of the word can appear at the left corner of the constituent we are working on:
leftcorner_recognize(Cat,[Word|StringIn],StringOut) :-
lex(Word,WCat),
lc(WCat,Cat),
complete(Cat,WCat,StringIn,StringOut).Similarly, we check that the left-hand sides of the rules we are using can appear as the left corner of the category we are building:
complete(Cat,SubCat,StringIn,StringOut) :-
LHS ---> [SubCat|Cats],
lc(LHS,Cat),
matches(Cats,StringIn,String1),
complete2(Cat,LHS,String1,StringOut). The other clause of complete is unchanged.
Now, go back to the example and check what happens. In step four, where the previous version of the algorithm made the mistake, this new version would check whether lc(TV,N) is true. Since this is not the case, it would immediately backtrack and find the second possibility for plant in the lexicon.