9.1 Left-Corner Parsing
We will now look at examples of top-down and bottom-up processing which show what kind of information we use to make decisions in these two different processing strategies, what kind of information we ignore with these strategies, and how it can happen that we go wrong, because of that.
9.1.1 Going Wrong with Top-down Parsing
Assume that we have the following grammar fragment
|
|
|
|
|
|
|
|
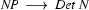
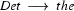
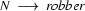
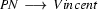
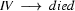
and that we want to use it to top-down recognize the string vincent died. Proceeding in a top-down manner, we would first expand 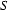 to
to 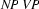 . Next we would check what we can do with the
. Next we would check what we can do with the 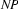 and find the rule
and find the rule 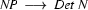 . We would therefore expand to
. We would therefore expand to 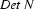 . Then we either have to find a lexical rule to relate vincent to the category
. Then we either have to find a lexical rule to relate vincent to the category 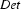 , or we have to find a phrase structure rule to expand . Neither is possible, so we would backtrack checking whether there are any alternative decisions somewhere.
, or we have to find a phrase structure rule to expand . Neither is possible, so we would backtrack checking whether there are any alternative decisions somewhere.
So, when recognizing in a top-down manner, we totally ignore what the actual input string looks like. We start from some non-terminal symbol and then use rules to rewrite that symbol. Only when we can't apply any rules anymore, we check whether what we have produced matches with the input string.
Here is part of the trace that we will get when trying to recognize vincent died with the top-down recognizer of the previous section. You can see how Prolog first tries to use the first rule 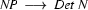 to expand the noun phrase. And only when Prolog realizes that leads into a dead-end does it try the next rule
to expand the noun phrase. And only when Prolog realizes that leads into a dead-end does it try the next rule 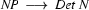 .
.
Call: (7) recognize_topdown(s, [vincent, died], []) ?
Call: (8) matches([np, vp], [vincent, died], []) ?
Call: (9) recognize_topdown(np, [vincent, died], _G579) ?
Call: (11) recognize_topdown(det, [vincent, died], _G585) ?
Fail: (11) recognize_topdown(det, [vincent, died], _G585) ?
Call: (11) recognize_topdown(pn, [vincent, died], _G582) ?
Exit: (11) recognize_topdown(pn, [vincent, died], [died]) ?
Exit: (9) recognize_topdown(np, [vincent, died], [died]) ?
Call: (10) recognize_topdown(vp, [died], _G582) ?
.
.
.9.1.2 Going Wrong with Bottom-up Parsing
As we have seen in the previous example, top-down parsing starts with some goal category that it wants to recognize and ignores what the input looks like. In bottom-up parsing, we essentially take the opposite approach: we start from the input string and try to combine words to constituents and constituents to bigger constituents using the grammar rules from right to left. In doing so, any consituents that can be built are built; no matter whether they fit into the constituent that we are working on a the moment or not. No top-down information of the kind ``we are at the moment trying to built a sentence'' or ``we are at the moment trying to built a noun phrase'' is taken into account. Let's have a look at an example.
Say, we have the following grammar fragment:
|
|
|
|
|
|
|
|
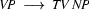
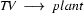
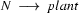
Note, how plant is ambiguous in this grammar: it can be used as a common noun or as a transitive verb. If we now try to bottom-up recognize the plant died, we would first find that the is a determiner, so that we could rewrite our string to Det plant died. Then we would find that plant can be a transitive verb giving us Det TV died. Det and TV cannot be combined by any rule. So, died would be rewritten next, yielding Det TV IV and then Det TV VP. Here, it would finally become clear that we took a wrong decision somewhere: nothing can be done anymore and we have to backtrack. Doing so, we would find that plant can also be a noun, so that Det plant died could also be rewritten as Det N died, which will eventually lead us to success.
9.1.3 Combining Top-down and Bottom-up Information
As the previous two examples have shown, using a pure top-down approach, we are missing some important information provided by the words of the input string which would help us to guid our decisions. However, similarly, using a pure bottom-up approach, we can sometimes end up in dead ends that could have been avoided had we used some bits of top-down information about the category that we are trying to build.
The key idea of left-corner parsing is to combine top-down processing with bottom-up processing in order to avoid going wrong in the ways that we are prone to go wrong with pure top-down and pure bottom-up techniques. Before we look at how this is done, you have to know what is the left corner of a rule. The left corner of a rule is the first symbol on the right hand side. For example, is the left corner of the rule 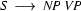 , and
, and 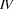 is the left corner of the rule
is the left corner of the rule 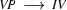 . Similarly, we can say that
. Similarly, we can say that 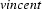 is the left corner of the lexical rule
is the left corner of the lexical rule 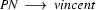 .
.
A left-corner parser alternates steps of bottom-up processing with top-down predictions. The bottom-up processing steps work as follows. Assuming that the parser has just recognized a noun phrase, it will in the next step look for a rule that has an as its left corner. Let's say it finds 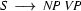 . To be able to use this rule, it has to recognize a
. To be able to use this rule, it has to recognize a 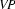 as the next thing in the input string. This imposes the top-down constraint that what follows in the input string has to be a verb phrase. The left-corner parser will continue alternating bottom-up steps as described above and top-down steps until it has managed to recognize this verb phrase, thereby completing the sentence.
as the next thing in the input string. This imposes the top-down constraint that what follows in the input string has to be a verb phrase. The left-corner parser will continue alternating bottom-up steps as described above and top-down steps until it has managed to recognize this verb phrase, thereby completing the sentence.
A left-corner parser starts with a top-down prediction fixing the category that is to be recognized, like for example 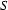 . Next, it takes a bottom-up step and then alternates bottom-up and top-down steps until it has reached an .
. Next, it takes a bottom-up step and then alternates bottom-up and top-down steps until it has reached an .
To illustrate how left-corner parsers work, let's go through an example. Assume that we again have the following grammar:
|
|
|
|
|
|
|
|
Now, let's look at how a left-corner recognizer would proceed to recognize vincent died.
1.) Input: vincent died. Recognize an . (Top-down prediction.)
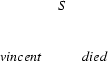
2.) The category of the first word of the input is 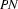 . (Bottom-up step using a lexical rule.)
. (Bottom-up step using a lexical rule.)
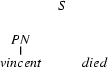
3.) Select a rule that has at its left corner: 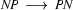 . (Bottom-up step using a phrase structure rule.)
. (Bottom-up step using a phrase structure rule.)

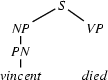
4.) Select a rule that has at its left corner: 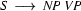 . (Bottom-up step.)
. (Bottom-up step.)
5.) Match! The left hand side of the rule matches with , the category we are trying to recognize.
6.) Input: died. Recognize a . (Top-down prediction.)
7.) The category of the first word of the input is . (Bottom-up step.)
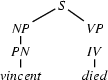
8.) Select a rule that has at its left corner: . (Bottom-up step.)
9.) Match! The left hand side of the rule matches with , the category we are trying to recognize.
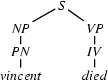
Make sure that you see how the steps of bottom-up rule application alternate with top-down predictions in this example. Also note that this is the example that we used earlier on for illustrating how top-down parsers can go wrong and that, in contrast to the top-down parser, the left-corner parser doesn't have to backtrack with this example.