8.2 Top Down Parsing
As we have seen, in bottom-up parsing/recognition we start at the most concrete level (the level of words) and try to show that the input string has the abstract structure we are interested in (this usually means showing that it is a sentence). So we use our CFG rules right-to-left.
In top-down parsing/recognition we do the reverse. We start at the most abstract level (the level of sentences) and work down to the most concrete level (the level of words). So, given an input string, we start out by assuming that it is a sentence, and then try to prove that it really is one by using the rules left-to-right. That works as follows: If we want to prove that the input is of category 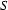 and we have the rule
and we have the rule 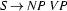 , then we will try next to prove that the input string consists of a noun phrase followed by a verb phrase. If we furthermore have the rule
, then we will try next to prove that the input string consists of a noun phrase followed by a verb phrase. If we furthermore have the rule 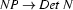 , we try to prove that the input string consists of a determiner followed by a noun and a verb phrase. That is, we use the rules in a left-to-right fashion to expand the categories that we want to recognize until we have reached categories that match the preterminal symbols corresponding to the words of the input sentence.
, we try to prove that the input string consists of a determiner followed by a noun and a verb phrase. That is, we use the rules in a left-to-right fashion to expand the categories that we want to recognize until we have reached categories that match the preterminal symbols corresponding to the words of the input sentence.
Of course there are lots of choices still to be made. Do we scan the input string from right-to-left, from left-to-right, or zig-zagging out from the middle? In what order should we scan the rules? More interestingly, do we use depth-first or breadth-first search?
In what follows we'll assume that we scan the input left-to-right (that is, the way we read) and the rules from top to bottom (that is, the way Prolog reads). But we'll look at both depth first and breadth-first search.
8.2.1 With Depth First Search
Depth first search means that whenever there is more than one rule that could be applied at one point, we explore one possibility and only look at the others when this one fails.
Let's look at an example. Here's part of the grammar ourEng.pl, which we introduced last week:
s ---> [np,vp].
np ---> [pn].
vp ---> [iv].
vp ---> [tv,np].
lex(vincent,pn).
lex(mia,pn).
lex(died,iv).
lex(loved,tv).
lex(shot,tv).The sentence ``Mia loved vincent'' is admitted by this grammar. Let's see how a top-down parser using depth first search would go about showing this. The following table shows the steps a top-down depth first parser would make. The second row gives the categories the parser tries to recognize in each step and the third row the string that has to be covered by these categories.

It should be clear why this approach is called top-down: we clearly work from the abstract to the concrete, and we make use of the CFG rules left-to-right.
And why was this an example of depth first search? Because when we were faced with a choice, we selected one alternative, and worked out its consequences. If the choice turned out to be wrong, we backtracked. For example, above we were faced with a choice of which way to try and build a VP --- using an intransitive verb or a transitive verb. We first tried to do so using an intransitive verb (at state 4) but this didn't work out (state 5) so we backtracked and tried a transitive analysis (state 4'). This eventually worked out.
8.2.2 With Breadth First Search
Let's look at the same example with breadth-first search. The big difference between breadth-first and depth-first search is that in breadth-first search we carry out all possible choices at once, instead of just picking one. It is useful to imagine that we are working with a big bag containing all the possibilities we should look at --- so in what follows I have used set-theoretic braces to indicate this bag. When we start parsing, the bag contains just one item.

The crucial difference occurs at state 5. There we try both ways of building VPs at once. At the next step, the intransitive analysis is discarded, but the transitive analysis remains in the bag, and eventually succeeds.
The advantage of breadth-first search is that it prevents us from zeroing in on one choice that may turn out to be completely wrong; this often happens with depth-first search, which causes a lot of backtracking. Its disadvantage is that we need to keep track of all the choices --- and if the bag gets big (and it may get very big) we pay a computational price.
So which is better? There is no general answer. With some grammars breadth-first search, with others depth-first.