3.2 Morphological Parsing
The goal of morphological parsing is to find out what morphemes a given word is built from. For example, a morphological parser should be able to tell us that the word cats is the plural form of the noun stem cat, and that the word mice is the plural form of the noun stem mouse. So, given the string cats as input, a morphological parser should produce an output that looks similar to cat N PL. Here are some more examples:
mouse | mouse N SG |
mice | mouse N PL |
foxes | fox N PL |
Morphological parsing yields information that is useful in many NLP applications. In parsing, e.g., it helps to know the agreement features of words. Similarly, grammar checkers need to know agreement information to detect such mistakes. But morphological information also helps spell checkers to decide whether something is a possible word or not, and in information retrieval it is used to search not only cats, if that's the user's input, but also for cat.
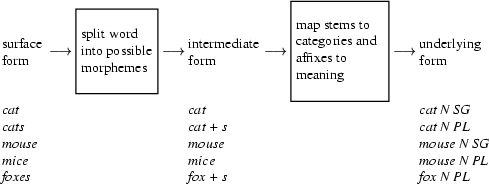
To get from the surface form of a word to its morphological analysis, we are going to proceed in two steps. First, we are going to split the words up into its possible components. So, we will make cat + s out of cats, using + to indicate morpheme boundaries. In this step, we will also take spelling rules into account, so that there are two possible ways of splitting up foxes, namely foxe + s and fox + s. The first one assumes that foxe is a stem and s the suffix, while the second one assumes that the stem is fox and that the e has been introduced due to the spelling rule that we saw above.
In the second step, we will use a lexicon of stems and affixes to look up the categories of the stems and the meaning of the affixes. So, cat + s will get mapped to cat NP PL, and fox + s to fox N PL. We will also find out now that foxe is not a legal stem. This tells us that splitting foxes into foxe + s was actually an incorrect way of splitting foxes, which should be discarded. But note that for the word houses splitting it into house + s is correct.
Here is a picture illustrating the two steps of our morphological parser with some examples.
We will now build two transducers: one to do the mapping from the surface form to the intermediate form and the other one to do the mapping from the intermediate form to the underlying form.
3.2.1 From the Surface to the Intermediate Form
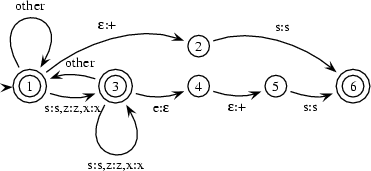
To do morphological parsing this transducer has to map from the surface form to the intermediate form. For now, we just want to cover the cases of English singular and plural nouns that we have seen above. This means that the transducer may or may not insert a morpheme boundary if the word ends in s. There may be singular words that end in s (e.g. kiss). That's why we don't want to make the insertion of a morpheme boundary obligatory. If the word ends in ses, xes or zes, it may furthermore delete the e when introducing a morpheme boundary. Here is a transducer that does this. The ``other'' arc in this transducer stands for a transition that maps all symbols except for s, z, x to themselves.
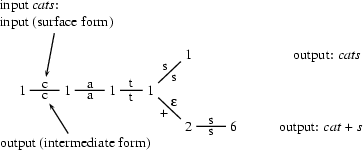
Let's see how this transducer deals with some of our examples. The following graphs show the possible sequences of states that the transducer can go through given the surface forms cats and foxes as input.
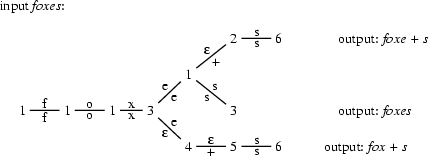
3.2.2 From the Intermediate Form to the Morphological Structure
Now, we want to take the intermediate form that we produced in the previous section and map it to the underlying form. The input that this transducer has to accept is of one of the following forms:
regular noun stem, e.g. cat
regular noun stem + s, e.g. cat + s
singular irregular noun stem, e.g. mouse
plural irregular noun stem, e.g. mice
In the first case, the transducer has to map all symbols of the stem to themselves and then output N and SG. In the second case, it maps all symbols of the stem to themselves, but then outputs N and replaces PL with s. In the third case, it does the same as in the first case. Finally, in the fourth case, the transducer should map the irregular plural noun stem to the corresponding singular stem (e.g. mice to mouse) and then it should add N and PL. So, the general structure of this transducer looks like this:
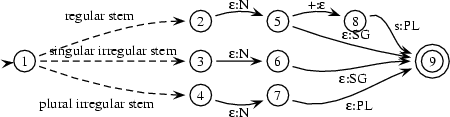
What still needs to be specified is how exactly the parts between state 1 and states 2,3, and 4 respectively look like. Here, we need to recognize noun stems and decide whether they are regular or not. We do this be encoding a lexicon in the following way. The transducer part that recognizes cat, for instance, looks like this:
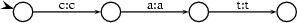
And the transducer part mapping mice to mouse can be specified as follows:
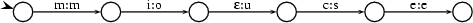
Plugging these (partial) transducers into the transducer given above we get a transducer that checks that input has the right form and adds category and numerus information.
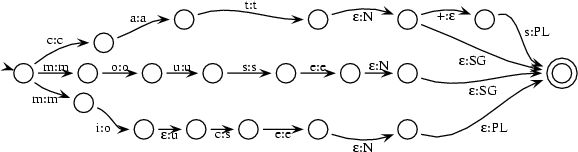
3.2.3 Combining the two Transducers
If we now let the two transducers for mapping from the surface to the intermediate form and for mapping from the intermediate to the underlying form run in a cascade (i.e. we let the second transducer run on the output of the first one), we can do a morphological parse of (some) English noun phrases. However, we can also use this transducer for generating a surface form from an underlying form. Remember that we can change the direction of translation when using a transducer in translation mode.
Now, consider the input berries. What will our cascaded transducers make out of it? The first one will return two possible splittings, berries and berrie + s, but the one that we would want, berry + s, is not one of them. The reason for this is that there is another spelling rule at work, here, which we haven't taken into account at all. This rule is saying that ``y changes to ie before s''. So, in the first step there may be more than one spelling rules that all have to be applied.
There are basically two ways of dealing with this. First, we can formulate the transducers for each of the rules in such a way that they can be run in a cascade. Another possibility is to specify the transducers in such a way that they can be applied in parallel.
There are algorithms for combining several cascaded tranducers or several transducers that are supposed to be applied in parallel into a single transducer. However, these algorithms only work, if the individual transducers obey some restrictions so that we have to take some care when specifying them.
3.2.4 Putting it in Prolog
If you want to implement the small morphological parser that we have seen in the previous section, all you really have to do is to translate the transducer specifications into the Prolog format that we used in the last lecture. Then, you can use last lecture's transducer program to let them run.
We won't show in detail what the transducers look like in Prolog, but we want to have a quick look at the e insertion transducer, because it has one interesting feature; namely, the other transition. How can we represent this in Prolog?
Here are all arcs going out of state 6 in Prolog notation, except for the other arc.
arc(6,2,z:z).
arc(6,2,s:s).
arc(6,2,x:x).
arc(6,3,'^':'^').Now, the other arc should translate any symbol except for z, s, x, ^ to itself. In Prolog, we can express this using cuts and exploiting the fact that Prolog searches the database top down:
arc(6,2,z:z) :- !.
arc(6,2,s:s) :- !.
arc(6,2,x:x) :- !.
arc(6,3,'^':'^') :- !.
arc(6,1,X:X) :- !.